Human Pose Estimation - Review on State-of-the-art Methods and Datatests
Human pose estimation (HPE) is the estimation of the configuration of human body parts from data captured by sensors. It provides geometric and motion information of the body and can be used in a large variety of applications such as autonomous driving, video surveillance, robotics, etc.
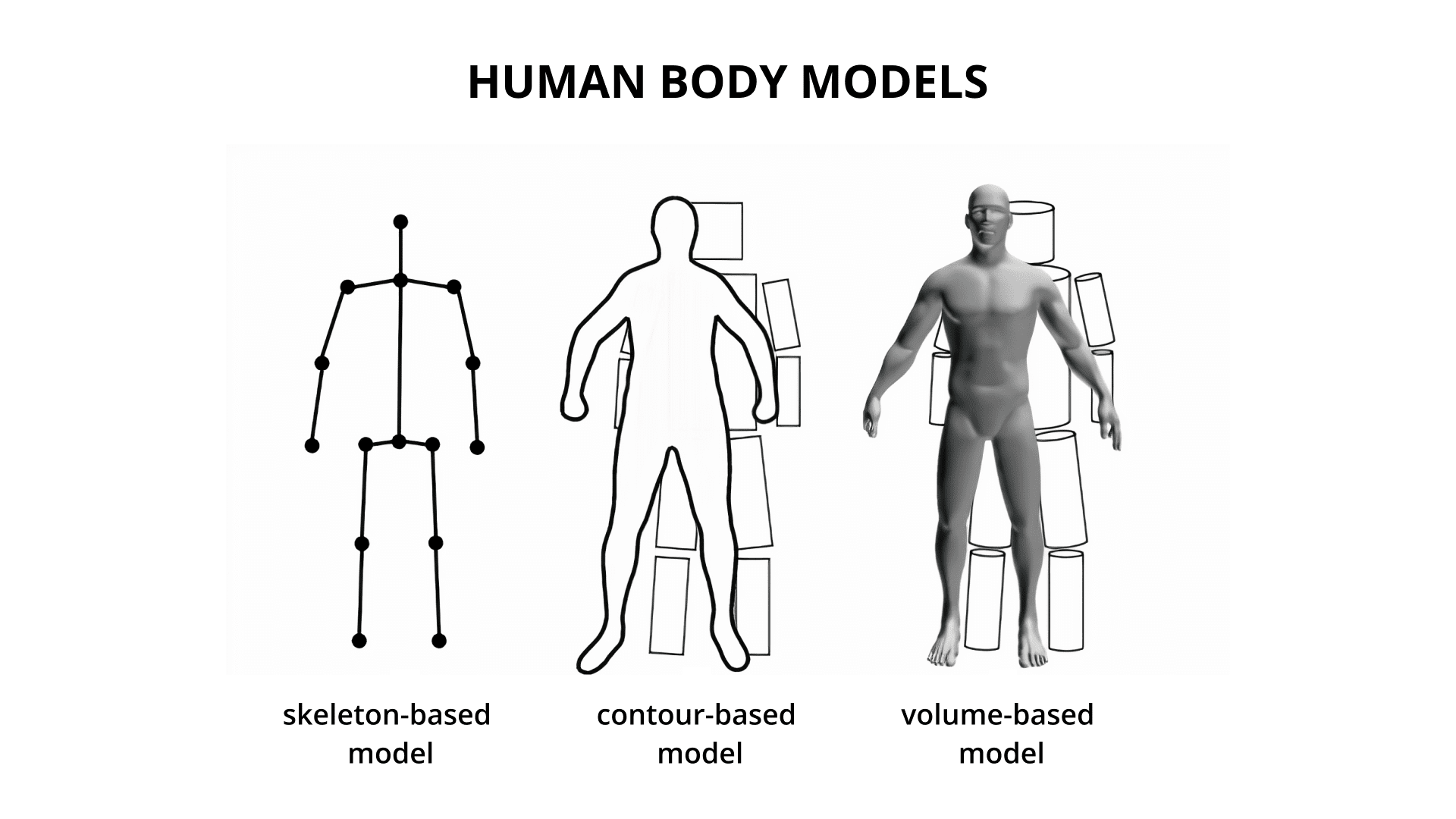
There are 3 different types of human body models that are used for human pose estimation. These models are represented in the following image.
HPE approaches
Human pose estimation can be divided into two main categories: 2D and 3D. 2D human pose estimation is when the pose of the humans is estimated in a two-dimensional image. 2D HPE can be single or multi person. Single person 2D HPE methods are usually regression methods, where it is applied an end-to-end framework to learn a mapping from the input image to body joints or parameters of human body models; and heatmap based methods, where locations of human body parts and joints are predicted, supervised by heatmap representation. Multi-person 2D HPE is divided in top down and bottom up approaches. Top-down methods employ off-the-shelf person detectors to obtain a set of boxes (each corresponding to one person) from the input images, and then apply single-person pose estimators to each person box to generate multi-person poses. Different from top-down methods, bottom-up methods locate all the body joints in one image first and then group them to the corresponding subjects. In the top-down pipeline, the number of people in the input image will directly affect the computing time. The computing speed for bottom-up methods is usually faster than top-down methods since they do not need to detect the pose for each person separately.
3D human pose estimation methods are more complex, and can be grouped in single view and single person; single view and multi person; multi person and multi view. Single view and person methods can be divided in human mesh recovery and skeleton only methods. The later can also be divided in direct estimation, where the 3D skeleton is retrieved directly from a 2D image, or 2D to 3D lifting, where the skeleton is detected in 2D, and then extrapolated to 3D. Similarly to 2D methods, single view and multi person 3D HPE can be grouped in top down and bottom up approaches. Multi view HPE is usually a combination of the previous methods.
Some of the more interesting existing methods are AlphaPose , DensePose, ViTPose, OpenPose, I2R-Net and Learnable human mesh triangulation for 3D human pose and shape estimation.
The main datasets with 3D labels are Human3.6M and MPI-INF-3DHP.Synthetic Data
The use of synthetic data to train models has been becoming more popular and reliable among learning. In the HPE field, there are also methodologies that take advantage of the synthetic data benefits, such as ease of acquisition and labelling. Example of this are Sim2real transfer learning for 3D human pose estimation: motion to the rescue , Synthetic Humans for Action Recognition from Unseen Viewpoints , Cross-Domain Complementary Learning Using Pose for Multi-Person Part Segmentation.
There are also synthetic human pose estimation datasets. The following are to be highlighted: SURREAL Dataset and GTA-IM Dataset.
RGB-D HPE
RGB-D HPE is not a very common study case among the HPE methods. Some authors explore its possibilities, for example TexMesh: Reconstructing Detailed Human Texture and Geometry from RGB-D Video, A2J: Anchor-to-Joint Regression Network for 3D Articulated Pose Estimation from a Single Depth Image, DoubleFusion: Real-time Capture of Human Performances with Inner Body Shapes from a Single Depth Sensor and Multi-view RGB-D Approach for Human Pose Estimation in Operating Rooms.
There are also several datasets that include the depth modalitity and 3D labels, such as Human3.6M, MuCo-3DHP, mRI and NTU RGB+D and NTU RGB+D 120
Point Cloud Feature Extraction
The goal of point cloud feature extraction is to build a segmentation map using a point cloud as an input. This work started with PointNet, where the methodology was able to find the different feature in a space without great detail. This method was later improved by PointNet++, which was able to differentiate more features in a tridimensional map. In 2022, the previous was again revised and PointNeXt was created. This method is able to detect fine details with great precision.
Current HPE Challenges
There are a lot of work already developed in HPE but challenges still remain and are transversal to both 2D and 3D HPE. The main current challenges are:
- Reliable detection of individual under occlusions
- Computation efficiency, mainly for cases that require real-time HPE and specially in 3D HPE (more demanding that 2d)
- Limited data for rare poses and model generalization for in the wild data
Experimenting with DensePose





